突然ですが、皆さんが今年検索エンジン最適化(SEO)のために取り組んだ施策を3つ挙げてみてください。
おそらく多くの方がキーワード調査にまつわるものを思い浮かべたのではないでしょうか。
SEOに関して、マーケティング担当者が通常真っ先に取り入れるのがそうした手法です。
![]()
確かにオーガニック検索における表示順位には効果が期待できますが、しかしこれだけで十分とはいえません。SEOにはもう1つ重要なカテゴリーが存在します。

テクニカルSEO用語辞典
〜検索順位とコンバージョン率改善のために知っておきたい用語を大公開〜
- 301リダイレクト
- 404エラー
- 504 Gateway Timeout
- XMLサイトマップ
今すぐダウンロードする
全てのフィールドが必須です。
内部SEOとは
内部SEOとは、ウェブサイトの構造、モバイル最適化、ページの表示速度など、ウェブサイト内部の技術的な要素を改善することで、オーガニックトラフィックの拡大を目指す施策を指します。難しく思えるかもしれませんが、極めて重要な取り組みです。
まず、ウェブサイトを精査して現状を把握し、その中で見つかった課題の改善プランを作成します。詳しい進め方については後ほど改めてご説明します。
内部SEO
内部SEOとは、ウェブサイトが検索エンジンにクロールおよびインデックス登録されやすくなるように講じる対策全般を言います。内部SEO、コンテンツ戦略、リンク構築戦略が全て作用し合うことで、ウェブサイトのページが検索結果の上位に表示されやすくなります。
内部SEOが重要な理由
SEOの技術的要素は難しいので無視してしまいたい気持ちに駆られるかもしれませんが、内部SEOはオーガニックトラフィックに関して重大な役割を担っています。考えに考え抜いて、役立つコンテンツを書き上げたとしても、検索エンジンにクロールされなければ、そのページが日の目を見ることはほとんどないでしょう。
例えるなら、1本の木が森の中で倒れるようなものです。周りに誰もいなければ、木が倒れる音に気付く人はいません。つまり、内部SEOの基礎をしっかりと築かなければ、コンテンツの存在を検索エンジンに認識してもらうことはできないのです。

それでは、インターネット上で自サイトを広く認知してもらう方法を確認していきましょう。
内部SEOの基本要素
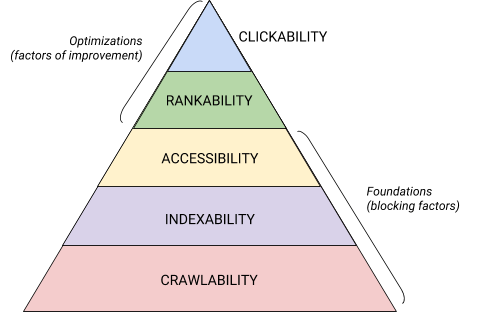
内部SEOは複雑で多岐に渡る、難易度の高いコンセプトなので、いくつかに分解して考えてみましょう。私と同じように、大きな課題に取り組む際にはそれを小分けにして、チェックリストに沿って進めたいと考える方も多いのではないでしょうか。実はここまで説明してきた内容は、5つのカテゴリーに分類でき、カテゴリーごとにやるべきことがあります。
内部SEOの5つのカテゴリーとそれぞれの位置付けは、以下の図で見事に表現されています。マズローの欲求階層(英語)を検索エンジン最適化バージョンに再構成したようなピラミッド図です(注:この図には「Accessibility(アクセシビリティー、アクセスしやすさ)」が使われていますが、この記事では一般的な「レンダリング」という単語を使っていきます)。
内部SEOはどうチェックする?
内部SEOの監査を始める前に、押さえておくべき基本がいくつかあります。
ウェブサイト監査の他の部分に進む前に確認しておきましょう。
優先ドメインを確認する
ドメインとは、URLの中のhubspot.jpなどの部分を指し、ウェブサイトにアクセスするために使われます。適切なドメインを使うことで、検索ユーザーの結果ページに自サイトが表示される可能性が高まったり、自サイト内のページであることを識別するのに役立ったりします。
優先ドメインを選択すると、検索結果ページに自サイトが表示されたとき、URLの頭に「www」が付いていても付いていなくても、訪問者はその優先ドメインにリダイレクトされます。例えば、yourwebsite.comではなくwww.yourwebsite.comを優先ドメインに指定すると、全ての訪問者がwww付きのバージョンにアクセスすることになります。優先ドメインを選択しないと、検索エンジンによってこの2つのバージョンは別のウェブサイトとして扱われるため、SEO評価が分散してしまいます。
かつて、Googleでは優先するURLのバージョンを指定する必要がありました。現在は検索ページに表示するドメインがGoogleによって選択されます。優先ドメインを任意で指定したい場合には、canonicalタグを使用します(canonicalタグについては後ほど説明します)。いずれにしても、全てのバージョンのURL(wwwあり、wwwなし、http、index.htmlなど)から適切なドメインにリダイレクトされることを確認しておきましょう。
SSLを導入する
「SSL」という単語は皆さんも聞いたことがあるでしょう。認知度の高さがその重要性を物語っています。SSLとはセキュア ソケット レイヤーの略称で、ウェブサーバー(オンラインリクエストを処理するソフトウェア)とブラウザーの間に保護レイヤーを設けることによって、ウェブサイトの安全性を確保する仕組みです。訪問者がウェブサイトに支払情報や連絡先などの情報を送信する際、SSLによって保護されることでこうした情報がハッキングされるリスクを抑えられます。
SSL対応のウェブサイトでは、ドメインが「http://」ではなく「https://」で始まり、アドレスバーに鍵のマークが表示されます。

検索エンジンではセキュリティー保護されたウェブサイトが優先されます。実際に、Googleは2014年の時点で検索順位の判定基準にSSLを利用すると発表(英語)しています。そのため、優先ドメインにはSSLに対応したバージョンのホームページを指定することを強く推奨します。
SSLのセットアップを終えたら、SSL非対応のページをhttpからhttpsに移行する必要があります。手間はかかりますが、検索順位を上昇させるためと思えばそれだけの価値はあるでしょう。移行の手順は次の通りです。
- http://yourwebsite.comの全ページからhttps://yourwebsite.comへのリダイレクトを設定します。
- それに合わせて、canonicalタグとhreflangタグを全て更新します。
- サイトマップ(yourwebsite.com/sitemap.xml)とrobot.txt(yourwebsite.com/robots.txt)の中のURLを更新します。
- Google Search ConsoleとBing Webmaster ツールの新しいインスタンスをセットアップして、httpsウェブサイトをトラッキングし、トラフィックが100%移行されていることを確認します。
ページの表示速度を最適化する
ウェブサイトにアクセスした訪問者は、ページが読み込まれるのを待つことになりますが、どれくらいまで待ってくれるかご存じですか。なんとたったの6秒(英語)です。多めに見積もってこの時間です。あるデータ(英語)によれば、ページの読み込み時間が1秒から5秒に増えると直帰率は90%増加します。1秒たりとも無駄にできないため、ウェブサイトの読み込み時間の短縮に優先的に取り組む必要があります。
ウェブサイトの表示速度が重要なのは、ユーザーエクスペリエンスやコンバージョンの観点からだけではありません。検索順位の判定基準(英語)にも含まれているのです。
ページの平均読み込み時間の短縮に関しては、以下のヒントを参考にしてください。
- 定期的にリダイレクトを精査する:301リダイレクトの処理には数秒かかります。リダイレクトが何ページまたは何層にもわたっていれば、それだけ処理時間が増し、表示速度に大きく影響します。
- コードをクリーンに保つ:雑然としたコードは、表示速度に悪影響を及ぼす恐れがあります。雑然としたコードとは冗長なコードのことです。これは文章を書くときと似ていて、最初は言いたいことをまとめるのに6文が必要でも、推敲によって3文に集約できるようなものでしょう。コードが効率的であるほど、ページの読み込み時間は短くなる傾向があります。コードをクリーンアップできたら、コードのミニフィケーションと圧縮(英語)を行います。
- コンテンツ配信ネットワーク(CDN)を検討する:CDNはさまざまな地域にウェブサイトのコピーを保存し、検索者の所在地に応じてウェブサイトを配信する分散型ウェブサーバーです。サーバー間で情報が移動する距離が短くなるため、リクエストしたユーザーに対してウェブサイトが表示されるまでの時間が短縮されます。
- むやみにプラグインを使用しない:最新でないプラグインはセキュリティー上の脆弱性を伴うことが多いため、ウェブサイトが悪意あるハッカーによる攻撃を受けやすくなり、ウェブサイトの検索順位にも影響が及びかねません。プラグインは厳選し、常に最新のバージョンを使用するように心がけましょう。同じく、既製のウェブサイトテーマには多数の不要なコードが含まれている場合が多いため、カスタムテーマの使用を検討されることをおすすめします。
- キャッシュ用プラグインを活用する:キャッシュ用プラグインは、ウェブサイトの静的バージョンを保存しておき、ユーザーが再度リクエストしたときにそれを送信することで、2回目以降の訪問時に読み込み時間を短縮します。
- 非同期読み込みを行う:スクリプトとは、ウェブページのHTMLまたは本文、つまり訪問者が目的としているコンテンツをサーバーが処理するために必要な指示のことです。例えばGoogle タグマネージャーのスクリプトのように、一般的にスクリプトはウェブサイトの<head>タグの中に書かれていて、ページの他の部分のコンテンツよりも優先されます。非同期コードを使うと、サーバーでHTMLとスクリプトを同時に処理できるため、遅延が減少してページの読み込み時間を短縮できます。
非同期スクリプトは、<script async src="script.js"></script>のように記述されます。
速度面における改善点を突き止めるには、Googleが提供するこちらのツール(英語)がおすすめです。
内部SEOの基本を押さえたら、次はピラミッドの1番下の層である「クロールされやすさ」を見ていきましょう。
クローラビリティーのチェックリスト
検索エンジンはボットを使ってページをクロール(巡回)し、ウェブサイトに関する情報を収集します。ウェブサイトのクロールされやすさを示すのが「クローラビリティー」です。クローラビリティーは、内部SEO戦略の土台となります。
何らかの理由でクロールが阻害されると、ページのインデックス登録やランク付けができなくなります。内部SEO導入の第一歩は、ボットが全ての重要なページにアクセスでき、簡単に巡回できるようにすることです。
ページのクロールされやすさを確保できるよう、チェックリストに欠かせない項目と、監査が必要なウェブサイト要素を以下にまとめました。
クローラビリティーのチェックリスト
- XMLサイトマップを作成する
- クロールバジェットを最大化する
- サイトアーキテクチャーを最適化する
- URL構造を設定する
- robots.txtを活用する
- パンくずリストを追加する
- ページネーションを行う
- SEOログファイルを確認する
1. XMLサイトマップを作成する
XMLサイトマップとは、ウェブサイトの構造が記されたXML形式のファイルです。検索ボットは、このファイルを参考にして、ウェブページの内容を理解してクロールします。つまり、ウェブサイトの地図のようなものです。サイトマップが完成したら、Google Search ConsoleとBing Webmasterツールに送信します。ウェブページの追加や削除を行った場合は、サイトマップも忘れずに最新の情報に更新しましょう。
2. クロールバジェットを最大化する
クロールバジェットとは、検索ボットがそのウェブサイト内でクロールできるページおよびリソースの上限数のことです。
クロールバジェットには限りがあるため、最も重要なページが優先的にクロールされるようにしましょう。
クロールバジェットを最大化するためのヒントとして、次のようなものがあります。
- 重複するページは削除するか、canonicalタグを使って正規化する
- リンク切れがあれば、修正またはリダイレクトする
- CSSファイルおよびJavaScriptファイルをクロール可能な状態にする
- クロール回数に急激な増減がないか、クロールの統計情報を定期的にチェックする
- 特定のボットやページのクロールを許可していない場合、その妥当性を確認する
- サイトマップを常に更新し、適切なウェブマスターツールに送信する
- ウェブサイトを整理して、不要なコンテンツや古いコンテンツを取り除く
- 動的URLを使うとウェブサイトのページ数が急増するリスクがある点に注意する
3. サイトアーキテクチャーを最適化する
ウェブサイトは複数のページで構成されているものです。これらのページを整理して、検索エンジンが見つけやすく、クロールしやすいようにする必要があります。そこで注目したいのがサイト構造です。ウェブサイトに情報をどのように掲載するのか設計することを指します。
建物が設計図を基に建てられるのと同じように、ウェブサイトのページはサイトアーキテクチャーに従って構成されます。
例えばブログなら、ホームページに各記事へのリンクを張り、記事内にはそれを書いた執筆者のページへのリンクを張ります。このように関連するページをグループ化することで、検索ボットがページ間の関係性を理解しやすくなります。
また、サイトアーキテクチャーは各ページの重要性を具現化したものであり、どのページが重要なのかがそのまま反映されている必要があります。ホームページと階層が近く、張られているリンク数が多く、そのリンク先にもリンクが多いページは、検索エンジンによって重要性が高いページだと評価されます。
ホームページからのリンクとブログ記事からのリンクでは、前者の方がそのページの重要性は高くなります。また、ページへのリンク数が多いほど、有用なページであると検索エンジンに示すことができます。
下図はサイトアーキテクチャーを大まかに図式化したものです。「会社概要」、「製品」、「ニュース」などのページが最も重要性が高く、階層の最上位に位置しています。
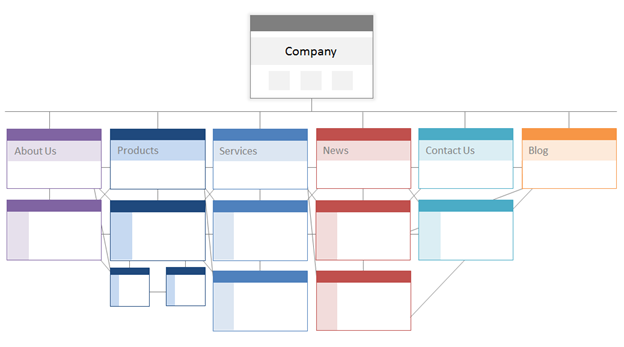
貴社にとって最も重要性の高いページを階層のトップに配置し、関連性の高い内部リンクの数も最多となるようにしましょう。
4. URL構造を設定する
URL構造とは、つまりURLがどのような作りになっているかということです。サイトアーキテクチャーによって決まる場合もあります。両者の関係については後ほど説明しますので、その前にURL構造について理解しておきましょう。URLでは、blog.hubspot.comなどのサブドメインや、hubspot.com/blogなどのサブディレクトリーを使って接続先が指定されます。
例えば、「愛犬が喜ぶブラッシング方法」というタイトルのブログ記事を公開する場合、ブログのサブドメインまたはサブディレクトリーに格納され、URLはwww.bestdogcare.com/blog/how-to-groom-your-dogのようになるでしょう。これを同じウェブサイト内に製品ページとして掲載する場合には、www.bestdogcare.com/products/grooming-brushなどのURLになります。
サブドメインとサブディレクトリーのどちらを使うのか、また「products」と「store」のどちらにするのかを決めるのは他でもない皆さん自身です。ウェブサイトを自作するメリットは、ルールを自分で決められる点にあります。重要なのはそのルールに一貫性を持たせることです。つまり、こっちの記事はblog.yourwebsite.com、あっちの記事はyourwebsite.com/blogsというように、ばらつきを生じさせないことが必要になります。ロードマップを作成してURLの命名規則に反映させ、それに従ってURLを決めましょう。
URLの命名規則に関するヒントをご紹介します。
- アルファベットは小文字のみ
- 単語と単語の区切りにはダッシュ(-)を使う
- 短く分かりやすいURLにする
- 不要な文字や単語は含めない
- ターゲットキーワードを含める
URLの構造が整ったら、重要なページのURLのリストをXMLサイトマップとして検索エンジンに送信します。そうすることで、検索ボットはウェブサイトの詳細が分かるため、クロールしながら構造を把握する必要がなくなります。
5. robots.txtを活用する
検索ボットがウェブサイトをクロールするとき、最初にチェックするのが「/robot.txt」です。ロボット排除プロトコルとも呼ばれます。このプロトコルは、特定のボットによるウェブサイト(全体または一部のセクションやページ)のクロールを許可または禁止します。また、ウェブサイトのインデックス登録を希望しないなら、noindex robotsメタタグを使用する方法もあります。クロールやインデックス登録の回避が必要になる場合について詳しく見ていきましょう。
まず、特定のボットによるクロールを全面的にブロックしたいケースが考えられます。というのも、コンテンツの収集やコミュニティーフォーラムへのスパム攻撃を目的として、悪意あるクロールを行うボットが一部存在するためです。こうした不正行為に気付いたら、robot.txtを使って該当するボットをウェブサイトに入れないようにします。この場合、robot.txtは、インターネット上の悪意あるボットからウェブサイトを守る防壁のようなものだと言えます。
検索ボットによるインデックス登録では、ウェブページを関連性の高い検索語句にマッチングさせられるよう、検索ボットがウェブサイトをクロールして情報を集め、キーワードを検出します。しかし、(詳細は後ほど説明しますが)限られたクロールバジェットを不要なデータに使うのは得策ではありません。ですから、ログインページやオファーダウンロード後に表示されるサンキューページなど、検索ボットがウェブサイトの内容を把握するのに役立たないページは除外した方がよいでしょう。
いずれにしても、robot.txtプロトコルはウェブサイトの目的に応じてそれぞれに違ったもの(英語)となります。
6. パンくずリストを追加する
「ヘンゼルとグレーテル」という童話に、2人の子どもが帰り道が分かるようにパンくずを落としていった場面がありましたね。このコンセプトがウェブサイトにも取り入れられています。
パンくずリストとはその名の通り、訪問者がウェブサイトの最初の地点に戻るためのルートを示すものです。現在開いているページと同じサイト内の他のページとの関係を明確にします。
この機能はウェブサイトにアクセスする訪問者のためだけでなく、検索ボットにも活用されます。
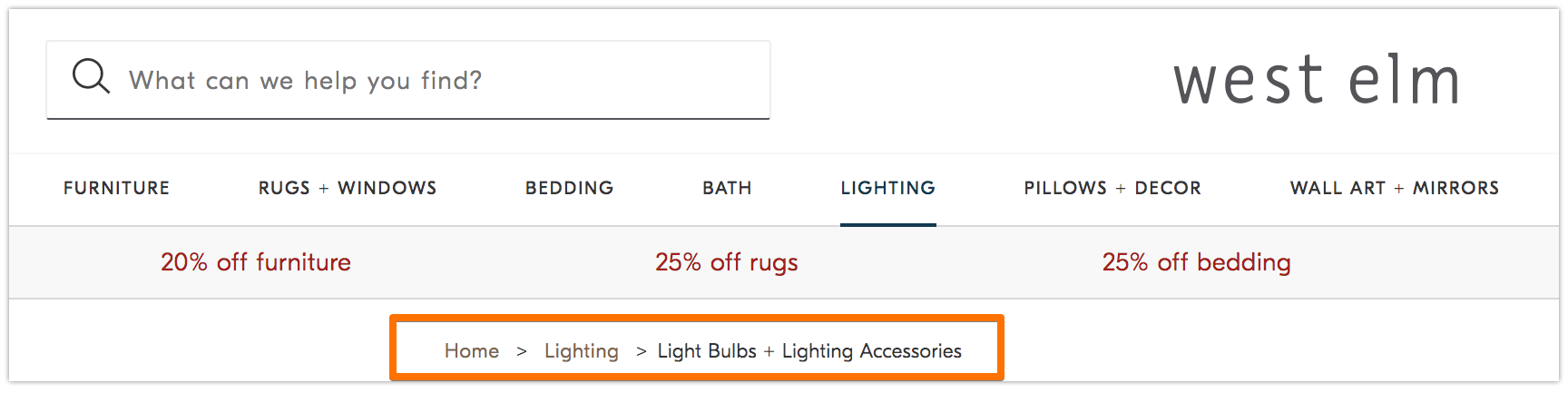
パンくずリストは次の2つの要件を満たす必要があります。
- 訪問者が[戻る]ボタンを使わなくても、ウェブページ内で迷わずに目的のコンテンツに到達できる
- 構造化マークアップ言語によって、検索ボットにウェブサイトの状況が正確に伝わる
構造化データをパンくずリストに追加する方法については、こちらのガイド(英語)で解説されています。
7. ページネーションを行う
学生時代を思い起こすと、提出するレポートにはページ番号を振るよう先生から教わりましたね。これをページネーションと呼びます。内部SEOにおいては若干役割が異なりますが、基本的にはページを整理する方法の1つと考えることができます。
ページネーションではコードを使い、異なるURLが互いに関連していることを検索エンジンに伝えます。例えば、シリーズもののコンテンツを章ごとに複数のウェブページに分けて掲載したとします。こうしたページを検索ボットが発見しやすく、クロールしやすくするために使用するのが、ページネーションです。
ページネーションの設定はごく簡単です。シリーズの1ページ目の<head>にrel=”next”を追加して、検索ボットに次にクロールすべきページを指示します。そして以降のページでは、rel=”prev”で前のページ、rel=”next”で次のページを設定していきます。
実際には次のようになります。
1ページ目
<link rel=“next” href=“https://www.website.com/page-two” />
2ページ目
<link rel=“prev” href=“https://www.website.com/page-one” />
<link rel=“next” href=“https://www.website.com/page-three” />
なお、ページネーションはボットに発見してもらいやすくなるという点では有効ですが、Googleによるページの一括インデックス登録ではサポートされなくなりましたのでご注意ください。
8. SEOログファイルを確認する
ログファイルは経理における仕訳入力のようなものです。ウェブサーバー(仕訳の入力者)が皆さんのウェブサイトに対して実行した全てのアクションに関するログデータを、ログファイル(仕訳帳)に記録し、保存します。リクエストの日時、リクエストされたコンテンツ、リクエスト元のIPアドレスなどのデータが記録されます。また、ユーザーエージェントも識別できます。ユーザーエージェントとは、ユーザーのリクエストを実行する、一意に識別可能なソフトウェア(検索ボットなど)です。
では、これがSEOとどのように関連しているのでしょうか。
検索ボットがウェブサイトをクロールすると、ログファイルにその痕跡が残ります。したがって、ユーザーエージェントと検索エンジンでフィルタリングしてログファイルを確認すれば、クロールされたかどうか、そしていつ、どのコンテンツがクロールされたのかが分かります。
クロールバジェットの消費状況や、ボットによるインデックス登録やアクセスの阻害要因を判断する材料としても有益な情報です。ログファイルにアクセスするには、開発者に問い合わせるか、Screaming Frog(英語)などのログファイル分析ツールを利用します。
検索ボットがウェブサイトをクロールできるからといって、必ずしも全てのページがインデックス登録されるとは限りません。そこで考慮したいのが、内部SEO監査の次の階層である「インデックス登録されやすさ」です。
インデキサビリティーのチェックリスト
検索ボットはウェブサイトをクロールしながら、トピックやそのトピックとの関連性の高さに応じてページをインデックス登録していきます。インデックス登録されると、SERP(検索エンジンの検索結果ページ)への表示対象となります。ページのインデックス登録されやすさ、つまり「インデキサビリティー」を高める要素を見ていきましょう。
インデキサビリティーのチェックリスト
- 検索ボットによるページへのアクセスをブロックしない
- 重複するコンテンツを削除する
- リダイレクトを精査する
- ウェブサイトのモバイル対応状況を確認する
- HTTPエラーを修正する
1. 検索ボットによるページへのアクセスをブロックしない
これについてはおそらく前述のクローラビリティーの段階で対処されるかと思いますが、大切なポイントなのでここでも取り上げておきます。検索ボットが優先ドメインにアクセスして自由に巡回できるようにすることが必要です。その対処法の1つとして、Googleのrobots.txtテスターを使って、検索ボットがアクセスできないページのリストを確認します。さらにGoogle Search ConsoleのInspectツールを使って、検索ボットがページにアクセスできない原因を突き止めることができます。
2. 重複するコンテンツを削除する
コンテンツが重複していると、検索ボットが混乱し、インデックス登録されにくくなります。canonical URLを使って、忘れずに優先ドメインを設定しましょう。
3. リダイレクトを精査する
全てのリダイレクトが適切に設定されていることを確認します。リダイレクトの繰り返しやリンク切れ、さらには不適切なリダイレクトが検出されると、ウェブサイトのインデックス登録に問題が生じる恐れがあります。このような事態を避けるためにも、リダイレクトは全て定期的に精査することをおすすめします。
4. ウェブサイトのモバイル対応状況を確認する
現時点でウェブサイトがモバイルに対応していないとしたら、大幅な後れを取っていると言わざるを得ません。早くも2016年にはGoogleがモバイルサイトを優先してインデックス登録するようになり、PCよりもモバイルでの使いやすさが重視され始めました。現在は、このインデックス登録方法がデフォルトで適用されています。この重要なトレンドに乗り遅れないよう、Googleのモバイル フレンドリー テスト(英語)を使ってウェブサイトのモバイル対応における改善点を特定しましょう。
5. HTTPエラーを修正する
HTTPはHyperText Transfer Protocolの略称です。しかし、重要なのは名前を覚えることではありません。どのような場合にHTTPからユーザーまたは検索エンジンにエラーが返されるのか、そしてそれを修正するにはどうすればよいかを理解することが必要になります。
HTTPエラーが発生すると、検索ボットがウェブサイト内の重要なコンテンツに到達できないため、検索ボットの動作を妨げかねません。このため、HTTPエラーに迅速かつ漏れなく対処することが極めて重要です。
HTTPエラーはそれぞれ異なるため、エラーごとに特定の方法で解消する必要があります。よって、以下のセクションでは各エラーについて簡単に説明するにとどめます。エラーの詳細と解消方法については以下のリンク先ページをご参照ください。
- 301 Permanent Redirects:あるURLから別のURLに永続的なリダイレクトが設定されている場合に返されるコードです。CMS(コンテンツ マネジメント システム)でこのリダイレクトの設定は禁止されていませんが、あまり多用するとリダイレクトが増えるたびにページの読み込み時間が延びるため、ウェブサイトの速度が落ちてユーザーエクスペリエンスが損なわれる恐れがあります。リダイレクトの繰り返しが多すぎると、検索エンジンがそのページのクロールを放棄してしまうため、複数回のリダイレクトが連なる「リダイレクトチェーン」は可能な限りゼロに抑えましょう。
- 302 Temporary Redirect:あるURLから別のウェブページに一時的なリダイレクトが設定されている場合のコードです。このステータスコードによって、訪問者は自動的に新しいウェブページにリダイレクトされますが、キャッシュに保存されるtitleタグ、URL、説明文(ディスクリプション)は元のURLのものとなります。ただし、一時的なリダイレクトを長期間設定したままにすると、最終的には恒久的なリダイレクトとして扱われるようになり、キャッシュにもリダイレクト先のURLのものが保存されます。
- 403 Forbidden:アクセス権限がない、またはサーバーの構成に誤りがあるために、リクエストしたコンテンツにアクセスできないことを意味します。
- 404 Not Found:ページが削除されたか入力したURLに誤りがあるかのいずれかの理由で、リクエストしたページが存在しないことを示します。このエラーに遭遇した訪問者が興味を失ってしまわないよう、会社のブランドイメージを打ち出した404エラーページを作成するとよいでしょう。
- 405 Method Not Allowed:アクセスメソッドがウェブサイトサーバーによって認識はされたものの、ブロックされた場合に発生するエラーメッセージです。
- 500 Internal Server Error:リクエストしたユーザーへのウェブサイト配信に関してウェブサーバー側で問題が生じていることを意味する、汎用エラーメッセージです。
- 502 Bad Gateway:ウェブサイトのサーバー間の通信状態に問題がある、または無効なレスポンスを受信したことを示すエラーメッセージです。
- 503 Service Unavailable:サーバーは正常に機能しているものの、リクエストを実行できないことを示します。
- 504 Gateway Timeout:サーバーがウェブサーバーから一定時間内にレスポンスを受信しなかったため、リクエストされた情報にアクセスできないことを意味します。
こうしたエラーの原因はさまざまですが、いずれの場合にも重要なのは、検索ユーザーと検索エンジンの両者に配慮し、再びウェブサイトを訪れてもらえるように対処することです。
たとえウェブサイトがクロールされ、インデックス登録されても、ユーザーやボットがアクセスできない状況だと、SEOにも影響が出てしまいます。では、内部SEO監査の次のステージである「レンダリングしやすさ」に進みましょう。
レンダラビリティーのチェックリスト
このトピックに入る前に取り上げておきたいのが、SEOにおけるアクセシビリティーとウェブアクセシビリティーの違いです。ウェブアクセシビリティーは、視覚障がいやディスレクシア(読み書きの障がい)などのあるユーザーも迷わずウェブページの目的のコンテンツに到達できることを指します。ウェブアクセシビリティーを向上するための要素は、多くがSEOにおけるベストプラクティスと重複します。一方、SEOにおけるアクセシビリティーに関する取り組みでは、障がいのあるユーザーにもアクセスしやすいウェブサイトづくりに必要な要素が全て考慮されるわけではありません。
このセクションではSEOにおけるアクセシビリティー=レンダラビリティーを取り上げますが、ウェブサイトの作成やメンテナンスに当たっては常にウェブアクセシビリティーを念頭に置くように心がけましょう。
アクセスしやすいウェブサイトの尺度となるのは、レンダリングのしやすさです。レンダリングしやすさ、レンダラビリティーを把握するには、以下のようなウェブサイト要素の確認が必要です。
サーバーパフォーマンス
上記で見たように、サーバーがタイムアウトしてエラーが発生するとHTTPエラーとなり、ユーザーやボットがウェブサイトにアクセスできなくなります。サーバーに問題が発生していることに気付いたら、トラブルシューティングを行い、問題を解決します。問題を速やかに解消できないと、検索エンジンによりウェブページのインデックス登録が解除される場合があります。これは、破損したページを表示するとユーザーエクスペリエンスが低下してしまうためです。
HTTPステータス
サーバーパフォーマンスに問題がある場合と同様に、HTTPエラーが発生した場合にもウェブページにアクセスできなくなります。Screaming Frog(英語)、Botify(英語)、Deepcrawl(英語)などのウェブクローラーを使用して、ウェブサイトの包括的なエラー監査を実施できます。
読み込み時間とページサイズ
ページ読み込みに時間がかかりすぎる場合に心配しなくてはならない問題は、直帰率だけではありません。ページの読み込みに時間がかかると、サーバーエラーが発生し、ボットがウェブページにアクセスできなくなったり、コンテンツの重要なセクションがまだ読み込まれていないバージョンをクロールすることになったりします。ボットによるページの読み込み、レンダリング、インデックス登録は、各リソースのクロール需要に応じて行われるものであり、ボットが使用するリソース量に変わりはありません。とはいえ、ページの読み込み時間を短縮するためにウェブサイト側でできるあらゆる対策を実施すべきです。
JavaScriptレンダリング
GoogleはJavaScript(JS)の即時処理の難しさを認めており、アクセシビリティーを向上させる手段としてあらかじめレンダリングされたコンテンツの採用を推奨しています。Googleでは、検索ボットがどのようにウェブサイトのJavaScriptにアクセスするのか、また検索に関連する問題を改善するにはどうしたらよいのかを理解する上で役立つさまざまなリソースを提供しています。
オーファンページ
ウェブサイト内のページは必ず他のページにリンクされている必要があります。少なくとも1つ、重要なページなら複数のリンクを設けることが推奨されます。内部リンクを持たないページは「オーファンページ」と呼ばれます(オーファンは英語で「孤児」)。前置きもなく本題に入る記事のように、オーファンページには、ボットがページをどのようにインデックス登録すべきかを理解するために必要な情報がありません。
ページの深さ
ページの深さとは、あるページがウェブサイトの構造の何層目に存在するか、つまり、ホームページからそのページに到達するまでに何回のクリックが必要かを指します。サイトアーキテクチャーができる限り深くならないこと、直観的な階層を維持することが理想です。ただし、どうしても多くの層で構成するほかない場合もあります。そのときには、深度を抑えることよりも、ウェブサイトの構成をすっきりと整理することを優先しましょう。
ウェブサイトを構成する層の数にかかわらず、製品ページや問い合わせページなどの重要なページは3クリック以内で到達できるようにします。製品ページがウェブサイト内の奥深くにあり、ユーザーやボットがまるで探偵にでもなったかのようにその場所を苦労して突き止めなければならないとしたら、アクセシビリティーが高いとは決して言えず、エクスペリエンスも損なわれます。
例えば、ターゲットの訪問者が製品ページにアクセスするためのウェブサイトURLが「www.yourwebsite.com/products-features/features-by-industry/airlines-case-studies/airlines-products」のようになっているなら、ウェブサイト構造の設計に問題があるでしょう。
リダイレクト
あるページから別のページにトラフィックをリダイレクトすることには代償が伴います。それとはクロール効率の低下です。リダイレクトが発生すると、クロール速度が低下し、ページの読み込み時間が延び、さらにリダイレクトが適切に設定されていなければウェブサイトにアクセスできなくなります。こうした全ての理由から、リダイレクトの数は最小限に抑える必要があるのです。
アクセシビリティーの問題に対処できたら、SERPでページの順位を向上させる方法に進みましょう。
ランカビリティーのチェックリスト
次に取り上げるのは、内部SEOにおけるランカビリティー、つまり検索上位への入りやすさを上げる方法です。よく話題になる要素なので、皆さんすでに意識されていることと思います。ページをSERPに表示させるには、冒頭で説明したオンページSEOとオフページSEOも必要となりますが、ここでは内部SEOの観点から解説します。
なお、全ての要素が組み合わさることでウェブサイトのSEO効果が発揮されるため、取りこぼしのないように注意が必要です。それでは詳しく見ていきましょう。
内部リンクと外部リンク
検索ボットはページのリンクをチェックすることによって、そのページが検索にヒットするページの中でどの辺りに位置付けているのかを理解し、ページの表示順位を判断します。リンクは、ボット(と訪問者)を関連コンテンツへと誘導し、リンク先ページの重要度を高める役割も果たします。一般的にはリンクを設定することで、クロールやインデックス登録のされやすさが向上し、検索ランクも上昇します。
バックリンクの質
バックリンクとは、外部サイトから張られたリンク(被リンク)のことで、自サイトが信頼に足るウェブサイトだとリンク元サイトから評価されている証左となります。バックリンクが設置されていると、検索ボットはクロールする価値のある良質なページだと判断します。バックリンクが多いほど、検索ボットに検出されやすくなり、信頼性の高いウェブサイトとして評価されます。ここまで読むと、バックリンクは素晴らしいものに思えますね。しかし、うまい話には条件がつきものです。信頼性の評価を高めるには、バックリンクの質が大きなポイントになります。
低質なウェブサイトからのリンクは、かえって表示順位に悪影響を与えかねません。良質なバックリンクの獲得を目指しましょう。例えば、関連性の高いコンテンツの発行元に働きかける、言及はされているもののリンクが設置されていない場合にリンクの設置を依頼する、関連性の高いコンテンツを提供する、外部サイトにリンクを設置したいと思ってもらえるような有益なコンテンツの作成に励むなど、さまざまな方法が考えられます。
コンテンツクラスター
HubSpotはコンテンツクラスターを重視しており、これまでもコンテンツクラスターがいかにオーガニックトラフィックの拡大に貢献するのかを発信してきました。コンテンツクラスターによって関連コンテンツをリンクさせることで、検索ボットが特定のトピックに関する全てのページを検出、クロール、インデックス登録しやすくなります。コンテンツクラスターは、あるトピックについての知見の豊富さをウェブサイト側から検索エンジンにアピールするツールとして機能します。このため、関連する検索語句が検索されたときに、権威あるウェブサイトとして上位に表示される可能性が高くなります。
オーガニックトラフィックを増やせるかどうかは、ランカビリティーにかかっています。検索ユーザーはSERPのうち上位3件目までのページをクリックする可能性が高い(英語)というデータが出ているためです。それでは、SERPでページをクリックしてもらうには、どうしたらよいのでしょうか。
その秘密を明らかにするため、オーガニックトラフィックのピラミッドにおける最上層「クリッカビリティー」を見ていきましょう。
クリッカビリティーのチェックリスト
クリックスルー率(CTR)は検索ユーザーの行動に起因するものですが、ウェブサイト側にもSERPでクリックしてもらえる可能性を高める方法はあります。キーワードを盛り込んだページタイトルやメタディスクリプションもクリックスルー率に効果を発揮しますが、ここでは今回のテーマである技術的要素に焦点を当てて見ていきます。
クリッカビリティーのチェックリスト
- 構造化データを使う
- SERP機能を制する
- 強調スニペット向けに最適化する
- Google Discoverを考慮する
検索ランクとクリックスルー率は連動します。なぜなら、人は何かを調べているとき、すぐに答えを知りたいものだからです。SERPで目立てば目立つほど、クリックされる可能性が上がります。そこで、クリックされやすさ、クリッカビリティーを向上させる方法をいくつか見ていきましょう。
1. 構造化データを使う
構造化データ(英語)では、検索ボットのためにスキーマと呼ばれる特殊な規格を使って、ウェブページの要素をカテゴリー分けし、ラベルを付けることができます。スキーマによって、各要素がどのようなもので、ウェブサイトにどう関連し、どう解釈されるべきかが非常に明白になります。つまり「これは動画」、「これは製品」、「これはレシピ」と検索ボットに伝え、解釈の余地を残さないようにするわけです。
誤解のないように説明しておくと、構造化データを使うこと自体は、クリッカビリティーを向上させる直接の要因にはなりません(そのような要因がそもそもあるならばの話ですが)。しかし、構造化データを使うとコンテンツが整理され、検索ボットにとってページを理解しやすく、インデックス登録しやすくなるため、検索ランクの上昇が期待できます。
2. SERP機能を制する
リッチリザルトとも呼ばれるSERP機能は、両刃の剣です。SERP機能を駆使してクリックスルー率が伸びたなら、申し分ありません。ところが、SERP機能を使いこなせなければ、オーガニック検索の結果ページで有料広告やテキスト形式の関連質問ボックス、カルーセル動画広告などの下に追いやられてしまいます。
通常の検索結果はページタイトル、URL、メタディスクリプションが表示されますが、リッチリザルトはその形式にとらわれません。下の例をご覧ください。2つのSERP機能、つまり動画のカルーセルと「People Also Ask(他の人はこちらも質問)」というボックスが上部に表示され、その下にオーガニック検索1位のページが表示されています。

オーガニック検索の結果でも上位に表示されればクリックを獲得できますが、リッチリザルトの方がその可能性は大幅に上がります。
どうすればリッチリザルトとして表示される確率を高められるのでしょうか。その答えは、役に立つコンテンツを作成すること、そして構造化データを使うことです。ウェブサイトの要素が検索ボットにとって理解しやすいほど、リッチリザルトに表示される可能性は高まります。
構造化データを使うと、以下の要素(と他の検索ギャラリー要素)がウェブサイトから取得されてSERPのトップに表示されやすくなるため、クリックスルーの確率が上がります。
- 記事
- 動画
- レビュー
- イベント
- ハウツー
- FAQ(「他の人はこちらも質問」ボックス)
- 画像
- ローカル ビジネス リスティング
- 製品
- サイトリンク
3. 強調スニペット向けに最適化する
スキーママークアップとの関連がない唯一のSERP機能が強調スニペットです。強調スニペットは検索結果の上に表示されるボックスで、検索内容に対する簡潔な答えを提示します。
強調スニペットは、検索ユーザーができる限り速く疑問を解消できるように表示されます。Googleのドキュメントによれば、強調スニペットとして表示されるためには、ユーザーの検索内容に合致する情報をページに掲載するほかないようです。しかしHubSpotの調査では、こちらの英語記事でご紹介している通り、他にも強調スニペットを獲得するためのコンテンツの最適化方法がいくつか明らかになっています。
4. Google Discoverを考慮する
Google Discoverは、モバイルユーザー向けの比較的新しい機能で、アルゴリズムを活用してカテゴリー別にコンテンツをリストアップします。Googleがモバイルエクスペリエンスに重点を置いていることはよく知られていますが、モバイルからの検索が50%を超えている(英語)ことを考えると、それも当然の流れでしょう。Google Discoverは、ユーザーが選択した関心のあるカテゴリー(ガーデニング、音楽、政治など)を基に、コンテンツのライブラリーを作成します。
HubSpotではトピッククラスターを作成することでGoogle Discoverへの表示の可能性を高められると考えており、この仮説を検証するため、Google Search ConsoleでGoogle Discoverトラフィックの積極的なモニタリングを行っています。この新機能について、皆さんも調査してみてはいかがでしょうか。Google Discoverにコンテンツが表示されるということは、皆さんが苦労して作り上げたコンテンツが、関連するトピックを自ら選択した極めてエンゲージメントの高いユーザー層に届くということです。その時間を割くだけの価値はあると思います。
内部SEOで地盤を整え、トラフィック拡大を
内部SEO、コンテンツSEO、外部SEOの3つが共に奏功することで、検索トラフィック拡大への道が開きます。内部SEOはウェブサイトを検索結果の上位に表示させ、コンテンツをターゲット層に届けるという点で極めて重要な役割を果たします。今回ご紹介した内部SEOの手法を参考にしながら、SEO戦略を完成させ、その成果を実感していただければ幸いです。
![]()